
Recently came across a plugin that does a superb performance by comparing two data frames in column-wise for structure file formats.
Explanation:
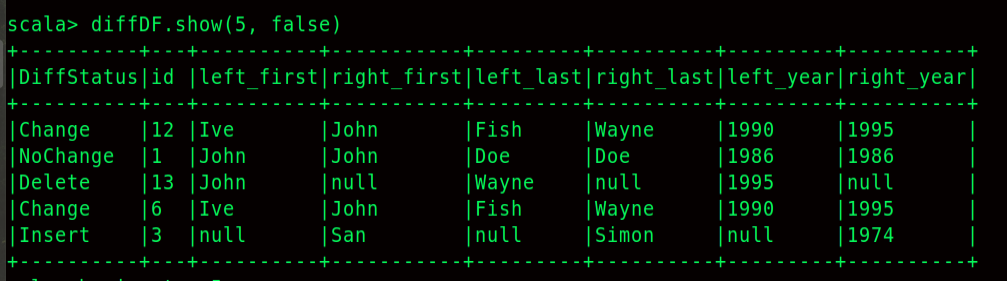
Code takes two data frames LEFT and RIGHT respectively and does a full outer join on all columns in the LEFT DF. Such if both records match then it is categorized as an UNCHANGED. If records are modified then it is categorized as INSERTED and if the record is not found it termed as DELETE
One of the advantages of using this script for the big data comparator tools. It is way faster than I expected. Also, you can see the mismatched records instantly by ordering by keys.
One more good point about the script is you can run in your spark-shell and compare two files.
It identifies Inserted, Changed, Deleted, and unchanged rows.
import java.util.Locale
import spark.implicits._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.internal.SQLConf
import org.apache.spark.sql.types.{ArrayType, StringType}
import org.apache.spark.sql.{Column, DataFrame, Dataset, Encoder}
/*
val df1 = Seq((1, "one"), (2, "two"), (3, "three")).toDF("id", "value")
val df2 = Seq((1, "one"), (2, "Two"), (4, "four")).toDF("id", "value")
df1.except(df2).union(df2.except(df1))
*/
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val columns = Array("id", "first", "last", "year")
val left = sc.parallelize(Seq(
(1, "John", "Doe", 1986),
(2, "Ive", "Fish", 1990),
(4, "John", "Wayne", 1995),
(5, "John", "Doe", 1986),
(6, "Ive", "Fish", 1990),
(7, "John", "Wayne", 1995),
(8, "John", "Doe", 1986),
(9, "Ive", "Fish", 1990),
(10, "John", "Wayne", 1995),
(11, "John", "Doe", 1986),
(12, "Ive", "Fish", 1990),
(13, "John", "Wayne", 1995)
)).toDF(columns: _*)
val right = sc.parallelize(Seq(
(1, "John", "Doe", 1986),
(2, "IveNew", "Fish", 1990),
(3, "San", "Simon", 1974),
(4, "John", "Doe", 1986),
(5, "Ive", "Fish", 1990),
(6, "John", "Wayne", 1995),
(7, "John", "Doe", 1986),
(8, "Ive", "Fish", 1990),
(9, "John", "Wayne", 1995),
(10, "John", "Doe", 1986),
(11, "Ive", "Fish", 1990),
(12, "John", "Wayne", 1995)
)).toDF(columns: _*)
// Record types
val insertRecord = "Insert"
val deleteRecord = "Delete"
val changeRecord = "Change"
val nochangeRecord = "NoChange"
val diffcolumnName = "DiffStatus"
// Left and Right column name
val leftColumn = "left_"
val rightColumn = "right_"
// PRIMARY KEY COLUMNS
val pkColumns = Seq("id")
def columnName(columnName: String): String =
if (SQLConf.get.caseSensitiveAnalysis) columnName else columnName.toLowerCase(Locale.ROOT)
def distinctStringNameFor(existing: Seq[String]): String = {
"_" * (existing.map(_.length).reduceOption(_ max _).getOrElse(0) + 1)
}
val pkColumnsCs = pkColumns.map(columnName).toSet
val otherColumns = left.columns.filter(col => !pkColumnsCs.contains(columnName(col)))
val existsColumnName = distinctStringNameFor(left.columns)
val l = left.withColumn(existsColumnName, lit(1))
val r = right.withColumn(existsColumnName, lit(1))
val joinCondition = pkColumns.map(c => l(c) <=> r(c)).reduce(_ && _)
val unChanged = otherColumns.map(c => l(c) <=> r(c)).reduceOption(_ && _)
val changeCondition = not(unChanged.getOrElse(lit(true)))
// DIff Condition
val diffCondition =
when(l(existsColumnName).isNull, lit(insertRecord)).
when(r(existsColumnName).isNull, lit(deleteRecord)).
when(changeCondition, lit(changeRecord)).
otherwise(lit(nochangeRecord)).
as(diffcolumnName)
// Find DIff Columns
val diffColumns =
pkColumns.map(c => coalesce(l(c), r(c)).as(c)) ++ otherColumns.flatMap(c =>
Seq(
left(c).as(s"$leftColumn$c"),
right(c).as(s"$rightColumn$c")
)).toList
val optionschangeColumn: Option[String] = None
val changeColumn =
optionschangeColumn.map(changeColumn =>
when(l(existsColumnName).isNull || r(existsColumnName).isNull, lit(null)).
otherwise(
Some(otherColumns.toSeq).filter(_.nonEmpty).map(columns =>
concat(
columns.map(c =>
when(l(c) <=> r(c), array()).otherwise(array(lit(c)))
): _*
)
).getOrElse(
array().cast(ArrayType(StringType, containsNull = false))
)
).as(changeColumn)
).map(Seq(_)).getOrElse(Seq.empty[Column])
val diffDF = l.join(r, joinCondition, "fullouter").select((diffCondition +: changeColumn) ++ diffColumns: _*)
diffDF.orderBy("id").show(25, false)
diffDF.groupBy(diffcolumnName).count().show()

{kind=link}
Comments
Post a Comment